
If you’ve ever needed to upload large files over SFTP, then you know how annoying connection drops and network timeouts can be. This guide will show you how to build a Python script that picks up from where you left off when your uploads get interrupted, hopefully saving you time and helping you avoid unnecessary stress.
This is a companion piece to our recent guide on resuming SFTP downloads. The concepts that we cover here are similar to our previous guide, so don’t worry, it’s not deja vu.
Instead of checking the remote file and appending to our local file, we check our local file and append to the remote file. By the end of this article, you’ll have a working SFTP upload script that handles interruptions with both standard SFTP servers, and S3 backed services like SFTP To Go.
What does “resume” mean for SFTP uploads?
Resuming SFTP uploads means continuing the transmission from where it left off if the upload gets interrupted. The SFTP protocol supports this functionality by using byte offsets (the exact position in bytes inside a file where you start reading or writing), but the client has to implement the logic. Here’s a basic run down of how it works:
- Check if a partial remote file exists (again, we use a .part file extension, but this time it gets created on the server )
- Get the file’s size in bytes
- Get the local file’s total size (this is the file that we will be checking our upload progress against)
- Open the local file and seek to the matching offset when resuming
- Read from that offset and append to the remote file
- Once the upload is done, we’ll rename the .part file to the final filename
This only works if the local file hasn’t changed since the upload started. If we modify the source file mid-upload, then the file being sent would not match and our upload would be corrupted. For this, we’ll add some verification to catch it.
Prerequisites
For this guide you’ll need Python 3.7+, Paramiko and Tenacity.
Connect to your SFTP server
The connection setup is the same as the download script. Here is a simple version using SSH key authentication:
Here are a few things about this setup:
- We use load_system_host_keys() to verify the server’s identity from ~/.ssh/known_hosts
- The RejectPolicy() will reject connections to unknown hosts
- Ed25519 keys are secure for SFTP, but you can swap to your preferred key type if you need to
If you see authentication errors, make sure that you added your public key to your SFTP server. For SFTP To Go, you can do this from the Dashboard > Credentials tab. You can check out the documentation for adding SSH keys for all the details of doing this for yourself.
Check file sizes
For uploads, we need to check our local file and the remote size of any potential partial upload files that didn’t complete:
The main difference from the download version of the script in our previous article is that we’re checking for the .part file on the server, and not locally. If a partial file does exist, then we’ll continue from that byte position.
Upload with resume support
Here’s a partial version of our script that shows the core upload logic. I’ve added a delay like last time so that you can press Ctrl+C to interrupt the upload yourself and see how the resume functionality works:
Here is the script running. We interrupted the upload several times and resumed each time until the upload completed.
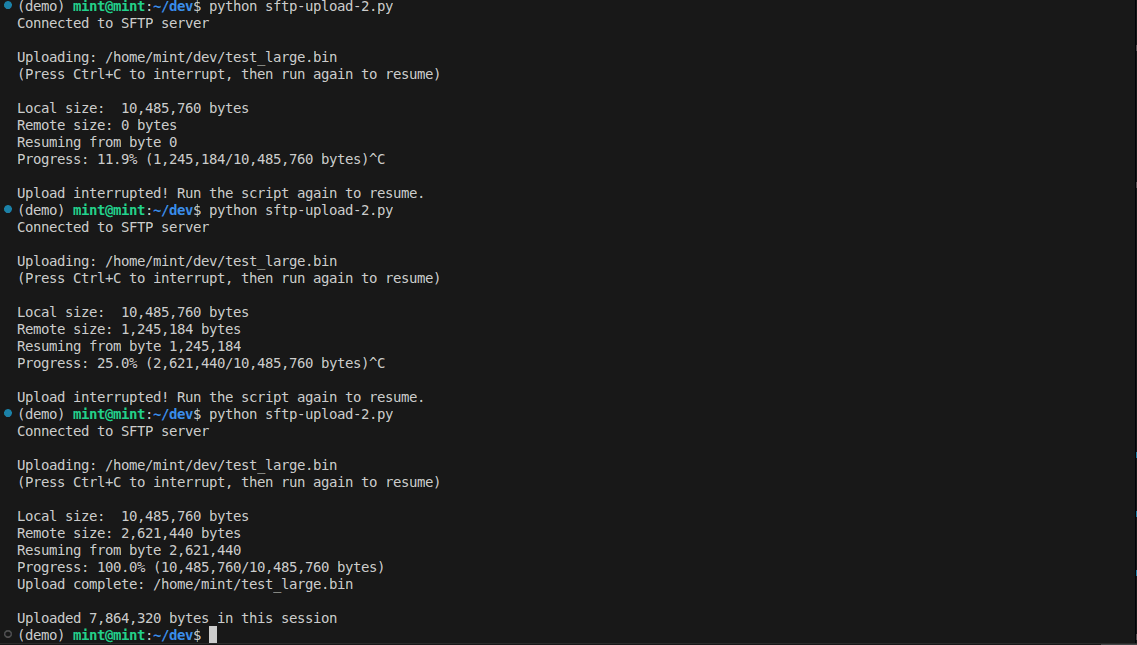
The key parts that cover the resume functionality are:
- sftp.open(part_path, ‘ab’) : This opens the remote file in append-binary mode and allows the file to be appended to
- local_file.seek(remote_size): This jumps to the byte offset where we left off
- We write to a .part file and only rename it to the actual file extension once the upload completes
- chunk_size=32768 uses 32kb chunks of data. You can experiment with these sizes, but 32kb gives us a good balance between memory usage and transfer efficiency
Handle connection drops with retry logic
We can wrap our upload function with automatic retry logic just like we did with the download script by using the tenacity library.
If your connection drops during the upload:
- The decorator catches the exception
- It waits 5 seconds before retrying
- It reconnects and calls upload_with_resume() again
- The resume function checks the .part file and carries on from there
Verify the local file hasn’t changed
Resuming only works if the local file stays the same throughout the upload. If the file is modified mid transfer, then you could end up with corrupted data on your target machine. That’s bad. We don’t like that.
To catch this, the script stores the local file’s size and modification timestamp in a .upload.meta file when the upload starts. On resume, it compares these values to the current file. If either has changed, the partial upload on the server is stale, so the script discards it and starts from fresh.
To be extra cautious with large files, you can add --verify tail, which checksums the last 1MB of the file before resuming. This catches edits that don't change the file size or timestamp, but adds a little overhead for very large files.
Choosing the chunk size
The chunk_size parameter can help you fine tune the script's performance if you have constraints like an ancient local or remote machine, or a glacially slow internet connection.
- Smaller chunks (8KB - 16KB): This will use less memory but will result in more round trips, making it slightly slower
- Larger Chunks (64KB - 128KB): You’ll use more memory but have fewer round trips. This has the potential to give you faster upload speeds if your connection is solid
- Default (32KB): This is the best balance, and it matches Paramiko’s default internal buffer size
For the majority of use cases, you won’t have to change this setting. If you’re uploading very large files over a stable connection then you can experiment with increasing the chunk size to see if you get any performance gains.
Complete script
Here is the script actually running. You can see that the remote file shows 0 bytes because nothing has been uploaded yet. I left the upload to run for a few minutes and then cancelled it. I launched it with these parameters:
I then resumed the upload and we can clearly see that the script identified the .part file and then resumed from byte 8,257,536.

Success! The upload then completed as per normal.

Troubleshooting
Here are some common issues that you might come across when you’re trying to upload to SFTP with resume support.
Host key verification failures
If you see this error:
All you need to do is add your host to your known_hosts like this:
Connection timeouts on large files
Sometimes a long-running upload can trigger idle timeouts on the server side. You might see common errors like:
or
The good news for us is that our retry logic handles this automatically. If you find your uploads failing a little too often, try adding SSH keep-alive:
Uploads finished but the remote file is corrupt
If the uploaded file is corrupted after resuming, the local file could have changed in between upload attempts. It’s not a common issue, but as we all know, in IT, anything is possible. To stop this from happening in the future we can use --verify tail for files that might be modified:
Permission denied on upload
If you see permission errors:
- Check that your SFTP user has write access to the upload-target directory
- Verify the remote path is correct and that it actually exists (ask me how I know to check for this one… It happens to the best of us).
- For SFTP To Go, check your credential's permissions in the Dashboard and make sure everything is configured correctly
Wrapping up
You now have a Python script that handles interrupted SFTP uploads! This means you don’t have to start from zero again when your connection drops.
Check out the sftptogo-examples repo on GitHub for the complete code. We’ll be adding a combined script that handles both uploads and downloads, so be sure to check back soon.
Looking for the download equivalent? See our companion guide: How to resume interrupted SFTP downloads in Python.
If you need to automate these transfers on a schedule then check out SFTP automation with tools like Cron To Go.
Frequently asked questions
What's the difference between sftp.put() and a custom resume script?
The built-in sftp.put() method uploads files in one shot with no resume support. If it fails mid-transfer, you will have to all start over again. That’s fine for small files, but if you are trying to upload something more substantial like a system image or large archives, then it’s no fun at all. Our handy script tracks progress with a .part file on the server, allowing you to continue on your merry way after failures.
How do I know if the local file changed during upload?
The script stores the local file's size, timestamp, or checksum in a .upload.meta file when the upload starts. It acts like a mini manifest of what you’re trying to upload. If our upload gets interrupted and we need to start again, we compare the information in the meta file to the current file. If they’re different, we throw out the partial upload and start fresh.
You can choose your verification method with the --verify flag:
- Size (default): fastest, works everywhere (Legacy SFTP and S3 backed cloud SFTP).
- Timestamp: fast, detects most modifications.
- Tail: checksums last 1MB, good balance of speed and reliability.
Can I resume downloads the same way?
Yes! Check out our companion guide: How to resume interrupted SFTP downloads in Python.
Why use a .part file on the server?
Using a .part extension tells us that the upload hasn’t completed yet, and that it is only partially done.
What's the size limit for SFTP uploads?
There's no practical limit in Paramiko. SFTP supports 64-bit file offsets, so theoretically you could upload exabytes. Real limits are your connection speed, server storage, and patience.
What happens if the script crashes halfway through the upload?
The .part file stays on the server exactly where it was. Run the script again and it resumes from that point.