
Industry
Cloud Data Integration
Headquarters
CA, USA
Company Size
11-50 Employees
Meet Xplenty
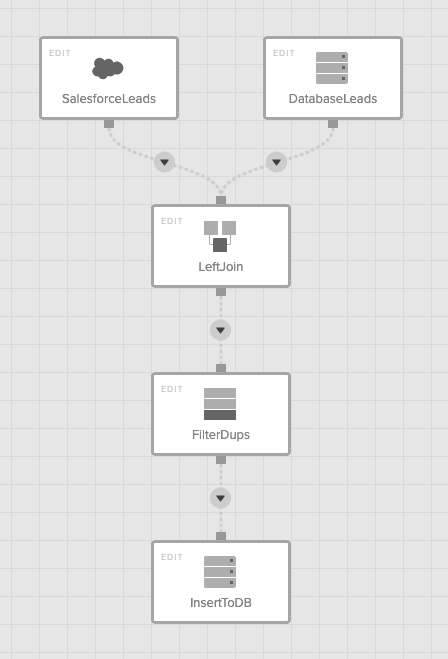
Xplenty is a leading cloud data integration platform, running millions of jobs on behalf of their customers and helping data flow from a variety of sources (including Salesforce, databases, files, and hundreds of SaaS products) into leading data warehousing solutions such as Amazon Redshift, Google BigQuery, Snowflake,Heroku Postgres and Salesforce Sales Cloud. Xplenty customers can, and more often than not, use Xplenty to also transform the data while it flows from the source and into destination to suit their BI needs. This includes splitting data into several destinations, joining multiple sources, filtering, aggregating and much more - in an intuitive graphical user interface that allows powerful transformations.
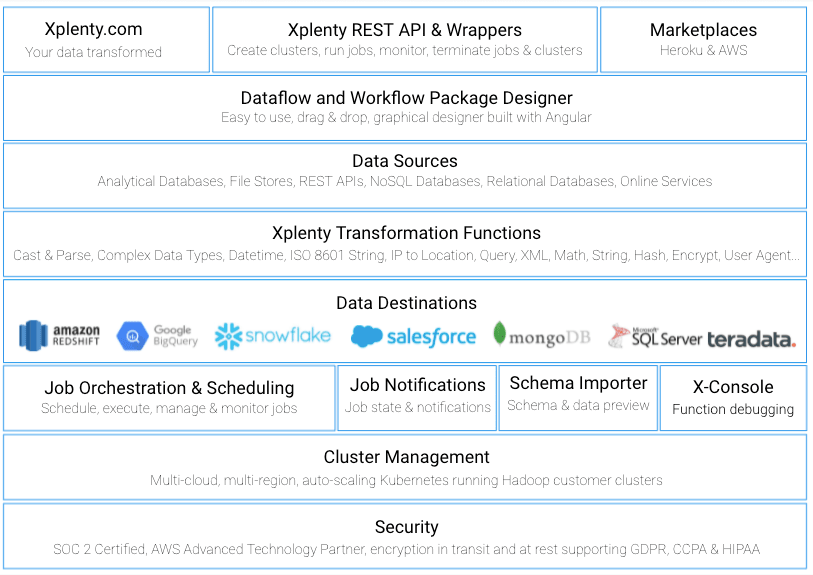
Founded in 2012, Xplenty was born in the cloud, or better yet in the clouds, utilizing multiple cloud platforms including Heroku and AWS Platforms. As part of its multi-cloud architecture, Xplenty is built up of many components that are split amongst the various clouds, depending on functionality. For instance, the interface, with which users build their dataflows, runs on Heroku, as well as the components that fetch preview data to help the user with the design of the dataflows. The actual dataflows run in containers on Kubernetes on AWS in an AWS region close to the customer’s data sources and destinations, as it’s beneficial to process data as close to the sources and/or destination as possible. Additionally, using Kubernetes makes it easier to automatically scale per customer job requirements. For the engineering team, this means that when working on a new source, for instance, a number of components must be developed e.g.UI, schema detection and data preview, job execution libraries, and others.
Xplenty’s Software Development Life Cycle
Xplenty’s value proposition for its users (intuitive GUI with powerful DSL for data transformations that allow infinite ways to combine sources and destinations) and its complex architecture, combined with maintaining mission critical 24/7 data flow, adds up to one very difficult task of maintaining software quality when adding new features and maintaining existing ones (fixing bugs or keeping up with source API changes for instance)
Xplenty’s engineering team came up with practices and processes that allow the product to remain agile all while maintaining high software quality and keeping excellent SLAs.
Testing, Testing, 1,2,3
Xplenty hosts its source code on GitHub. The team works in feature branches and when it’s time to build and test a feature, the CI/CD processes kick in automatically in Codeship, building docker images and pushing changes to the Heroku staging environment. Once the build is complete, automatic test processes create accounts within the new environment and test out the features. Some run UI tests using Selenium, while others create dataflows using Xplenty’s APIs, and then run them to check that the clusters are working properly after the changes were made. Additionally, the tests ensure that sources, destinations, and data transformations work well by checking that job output is valid, which is achieved by comparing it to previous outputs using more Xplenty dataflows. Clearly eating your own dog food as part of automatic QA is not something any R&D team can do, it does work great for Xplenty.
Testing Sources
We currently use SFTP To Go on our E2E tests before releasing code to production to make sure our ETL connectors are working. We also use Big Data for testing purposes and SFTP To Go never fails when it comes to connectivity compared to the traditional SFTP.
(Mark Smallcombe, Xplenty CTO)
During the automation tests, sources and destinations are also created (and eventually destroyed). For instance, databases and Redshift clusters are created and populated with data using dataflows. SFTP To Go is used to simulate 3 different file storage protocols (SFTP, FTPS and S3) for both reading and writing data. Since SFTP To Go is very scalable and its storage relies on S3, it allows Xplenty’s team to test big data processing using multiple connections for concurrent data read/write, which requires reliable connectivity but also allows Xplenty to test connectivity errors and read/write retries. Overall, SFTP’s reliability and versatility gives it its desirable edge for Xplenty to test the many moving parts that make up their product.
We also use Activity To Go as part of our SDLC to send Slack notifications to a dedicated channel so everyone is informed when something is pushed to production. Activity To Go also archives the data on S3 for auditing purposes.
(Mark Smallcombe, Xplenty CTO)
These tests take time, so it’s good to inform the team on progress and also keep track of it to comply with SOC2 requirements. To do this, the team uses Activity To Go, which sends messages to a Slack channel and also stores a log of all activities and changes to Amazon S3 cloud storage so that an audit log is there to help if anything were to go wrong.
Take Away
Xplenty’s dev team knows how important it is to design a process to maintain great quality of their product. They rely on automation, Heroku, and Heroku Add-ons such as SFTP To Go and Activity To Go to minimize the risks of breaking any of their components. Xplenty’s engineering team has developed processes that allow it to anticipate and test for defects in a highly complex environment to avoid downtime and constantly improve functionality and data quality.